
【AAAI 2024】再创佳绩!阿里云人工智能平台PAI多篇论文入选
近期,阿里云人工智能平台PAI发表的多篇论文在AAAI-2024上正式亮相发表。AAAI(AAAI Conference on Artificial Intelligence)是由国际人工智能促进协会主办的年会,是人工智能领域中历史最悠久、涵盖内容最广泛的国际顶级学术会议之一,也是中国计算机学会(CCF)推荐的A类国际学术会议。会议一直是人工智能界的研究风向标,在学术界久负盛名。
论文成果是阿里云与浙江大学、华南理工大学联合培养项目等共同研发,深耕以通用人工智能(AGI)为目标的一系列基础科学与工程问题,包括多模态理解模型、小样本类增量学习、深度表格学习和文档版面分析任务等等。此次入选意味着阿里云人工智能平台PAI自研的深度学习算法达到了全球业界先进水平,获得了国际学者的认可,展现了阿里云人工智能技术创新在国际上的竞争力。
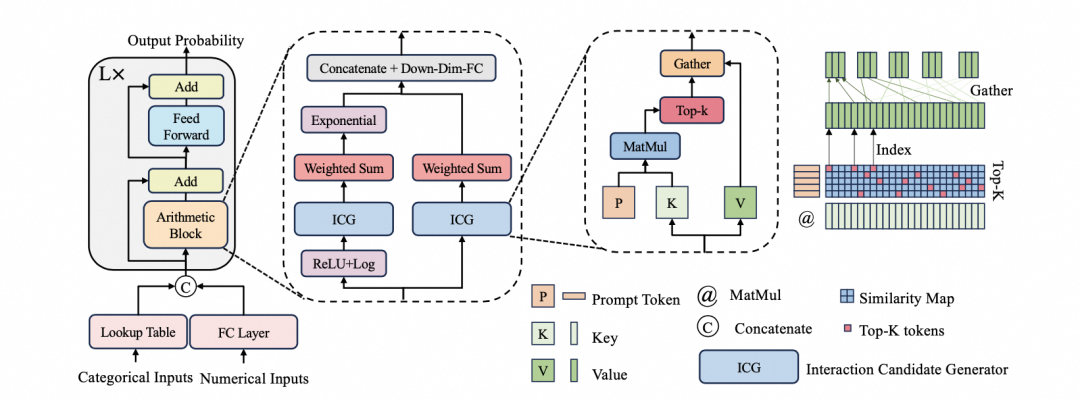
解锁深度表格学习(Deep Tabular Learning)的关键:算术特征交互
本文聚焦于研究深度模型在表格数据上的有效归纳偏置(inductive bias)。结构化表格数据广泛存在于各行业数据库和金融、营销、推荐系统等场景。这类数据包含数值和类别特征,常有缺失值、噪声及类别不均衡等问题,且缺乏时序性、局部性等对模型有益的先验信息,带来显著分析挑战。树集成方法(如XGBoost、LightGBM、CatBoost)凭借对数据质量问题的鲁棒性,在工业界的实际建模中占主导地位,但其性能很大程度上仍依赖于精心设计的特征工程处理。
学者们积极尝试将深度学习应用于端到端的表格数据分析,旨在减少对特征工程的依赖。现有相关工作包括:(1)结合传统建模方法并叠加深度学习模块(如多层感知机MLP)的方法,如Wide&Deep、DeepFMs;(2)采用深度学习对形状函数进行建模的广义加性模型变体,如NAM、NBM、SIAN;(3)受树结构启发的深度模型,如NODE、Net-DNF;(4)基于Transformer架构的模型,如AutoInt、DCAP、FT-Transformer。尽管上述努力不断推进,深度学习在表格数据上相较于树模型并未展现出持续且显著的优势,其有效性问题悬而未决。
我们提出,算术特征交互对于深度表格学习至关重要的理论。当前深度表格学习方法效果欠佳的核心症结在于未能发掘出有效的内在模型偏置。我们创新性地将算术特征交互理念融入Transformer架构内,通过引入并行注意力机制和提示标记的设计创建AMFormer架构。合成数据的结果展示了该模型在在精细表格数据建模、训练数据效率以及泛化方面的卓越能力。此外,进一步在真实世界数据集上开展的大规模实验,也验证了AMFormer的一致有效性和优越性。因此,我们相信,AMFormer为深度表格学习设定了强有力的归纳偏置,有望推动该领域的深入发展。
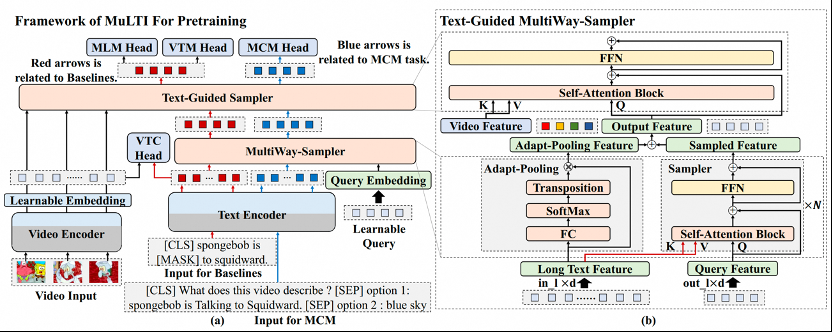
MuLTI:高效视频与语言理解
多模态理解模型在多标签分类、视频问答和文本视频检索等领域应用广泛,但多模态理解面临两大挑战:无法有效地利用多模态特征与GPU内存消耗大。模型通常由文本编码器、视频编码器及特征融合模块构成,其中后两者计算成本较高。以往方法如VIOLET和Clover直接连接两编码器输出并通过Transformer融合,导致显存消耗随输入增长急剧上升。为降低计算负担,ALPRO、FrozenBiLM、CLIPBert等研究尝试通过压缩视频特征,但这可能丢失关键信息。
我们提出了MuLTI模型,旨在实现高效准确的视频与语言理解,用于解决特征融合的难题。MuLTI采用自适应池残差映射和自注意机制设计了文本指导的多路采样器(Text-Guided MultiWay-Sampler),对文本的长序列进行采样并融合多模态特征,有效降低了计算成本且避免了压缩视频导致的性能下降。此外,为了进一步降低预训练任务和下游任务之间的差距,我们创新性地构建文本视频问答对引入了多选建模(Multiple Choice Modeling,MCM)预训练任务,以提升模型在视频问答中对齐视频与文本特征的能力。
最终,凭借高效的特征融合模块和新的预训练任务,MuLTI在多个数据集上取得了最先进的性能表现。
M2SD:多重混合自蒸馏用于小样本类增量学习
小样本类增量学习(Few-shot Class Incremental Learning, FSCIL)是机器学习领域中一项极具挑战的任务,目标在于仅利用有限数据学习新类别,同时保留对已学类别的记忆,无需重新训练模型。针对此难题,本文提出了一种创新策略,称为多重混合自蒸馏(Multiple Mixing Self-Distillation, M2SD)。该策略设计了双分支结构以有效扩展特征空间接纳新类别,并引入特征增强机制通过自蒸馏过程优化基础网络,从而在学习新类别时显著提升分类性能,最终仅保留主干网络进行高效识别。
FSCIL任务的关键挑战在于如何平衡小样本学习的过拟合和类增量学习的灾难性遗忘。为解决这一问题,我们提出一种创新的方法——多重混合自蒸馏(M2SD),旨在构建一个能适应新类别的高可扩展性特征空间。通过多尺度特征提取与融合技术,M2SD全面捕获数据实例的多维度信息,增强了模型的包容性。此外,我们创新性地采用双分支“虚拟类”机制,进一步提高特征模块的扩展能力,使得模型能够预适应未来新增类别并为其预留特征空间,从而强化模型对新类别的适应性和类增量学习的稳健性与灵活性。
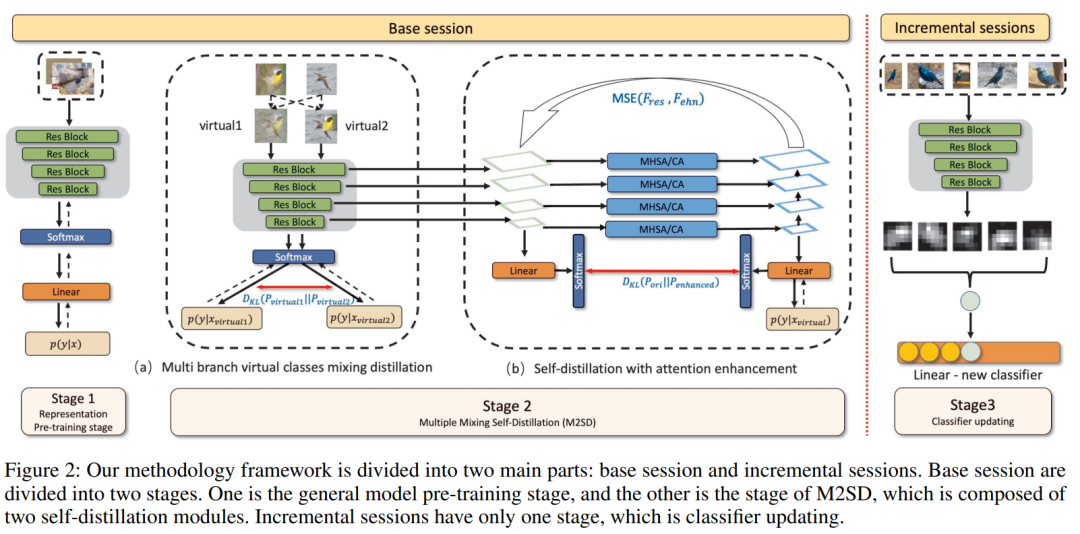
方法框架分为两个主要部分:Base session和Incremental sessions。Base session分为两个阶段。一个是通用模型预训练阶段(General model pre-trainining),另一个是M2SD阶段,由两个自蒸馏模块组成。Incremental sessions只有一个阶段,即分类器更新(Classifter updating)。
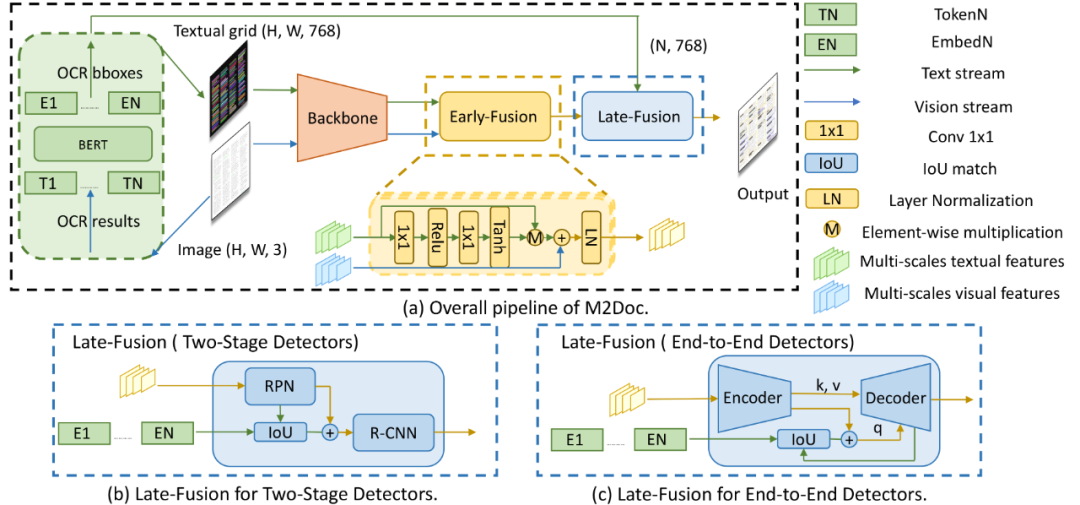
M2Doc:文档版面分析的可插拔多模态融合方法
文档版面分析是文档智能研究的核心课题,但现有众多方法主要依赖通用目标检测技术,其在处理过程中仅侧重于视觉特征表达,而对文本特征的内在价值关注不足。近年来,尽管多模态的预训练文档智能模型在多种下游任务中展现出卓越性能,但在处理文档版面分析这一特定的下游任务时,只局限于将多模态预训练好的主干网络迁移至纯视觉目标检测器进行微调,从本质上来说依然是个单模态的解决范式。
为此,本文创新性地提出了一种可插拔的多模态融合方案——M2Doc,旨在赋能纯视觉目标检测器以捕获并融合多模态信息的能力。M2Doc框架内嵌了两个关键融合模块:Early-Fusion与Late-Fusion。前者采用类似门控机制的设计,巧妙融合主干网络提取出的视觉和文本两种模态特征;后者则运用直接加和运算策略,有效融合了框级的文本及视觉特征。
得益于M2Doc简洁高效且具有普适性的模型结构设计,它能够便捷地适应多种目标检测器架构。实验结果证实,在DocLayNet与M6Doc等版面分析基准数据集上,融入M2Doc的目标检测器实现了显著性能提升。并且,当DINO目标检测器与M2Doc相结合时,在多个数据集上均达到了当前最优(SOTA)水平。
阿里云人工智能平台 PAI 多篇论文入选 AAAI 2024
● 论文标题:
Arithmetic Feature Interaction is Necessary for Deep Tabular Learning
● 论文作者:
程奕、胡仁君、应豪超、施兴、吴健、林伟
● 论文PDF链接:
https://arxiv.org/abs/2402.02334
● 代码链接:
https://github.com/aigc-apps/AMFormer
● 论文标题:
MuLTI: Efficient Video-and-Language Understanding
● 论文作者:
刘波、陈云阔、程孟力、徐家琪、施兴
● 论文PDF链接:
https://arxiv.org/abs/2303.05707
● 论文标题:
M2SD: Multiple Mixing Self-Distillation for Few-Shot Class-Incremental Learning
● 论文作者:
林今豪、吴梓恒、林炜丰、黄俊、罗荣华
● 论文标题:
M2Doc: A Multi-modal Fusion Approach for Document Layout Analysis
● 论文作者:
张宁、郑晓怡、陈佳禹、江宗源、黄俊、薛洋、金连文