
阿里云人工智能平台PAI多篇论文入选EMNLP 2023
近期,阿里云人工智能平台PAI主导的多篇论文在EMNLP2023上入选。EMNLP是人工智能自然语言处理领域的顶级国际会议,聚焦于自然语言处理技术在各个应用场景的学术研究,尤其重视自然语言处理的实证研究。该会议曾推动了预训练语言模型、文本挖掘、对话系统、机器翻译等自然语言处理领域的核心创新,在学术和工业界都有巨大的影响力。此次入选意味着阿里云人工智能平台PAI自研的自然语言处理算法达到了全球业界先进水平,获得了国际学者的认可,展现了中国人工智能技术创新在国际上的竞争力。
论文简述
面向Stable Diffusion的自动Prompt工程算法BeautifulPrompt
文生图是AIGC中最引人注目和广泛应用的技术之一,旨在通过文本输入创建逼真的图像。然而,文成图模型要求用户在模型推理之前编写文本提示(例如“一艘雄伟的帆船”)。编写满足设计师或艺术工作者需求的这些提示充满了不确定性,就像开盲盒一样。这是由于训练数据的质量问题,导致需要详细的描述才能生成高质量的图像。在现实场景中,非专家往往很难手工编写这些提示,并且需要通过试错的迭代修改来重新生成图像,从而导致时间和计算资源的严重浪费。BeautifulPrompt模型关注于大语言模型(LLM)自动地生成高质量的提示词,与InstructGPT类似,采用了三阶段的训练方式。下图展示了使用简单的图片描述和BeautifulPrompt之后生产的图片:

为了验证BeautifulPrompt的有效性,我们在一些基于模型打分的客观指标和人类主观评估上做了评测,结果验证了BeautifulPrompt显著提升了提示词的质量,可以生成高质量的图像。
面向垂直领域的知识预训练语言模型
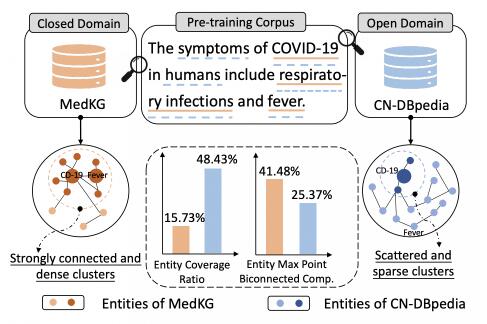
知识增强预训练语言模型(KEPLM)通过从大规模知识图(KGs)中注入知识事实来提高各种下游NLP任务的性能。然而,由于缺乏足够的域图语义,这些构建开放域KEPLM的方法很难直接迁移到垂直领域,因为它们缺乏对垂直领域KGs的特性进行深入建模。如下图所示,KG实体相对于纯文本的覆盖率在垂直领域中明显低于开放域,表明领域知识注入存在全局稀疏现象。这意味着将检索到的少数相关三元组直接注入到PLM中对于领域来说可能是不够的。我们进一步注意到,在垂直领域KGs中,最大点双连通分量的比率要高得多,这意味着这些KGs中同一实体类下的实体相互连接更紧密,并表现出局部密度特性。
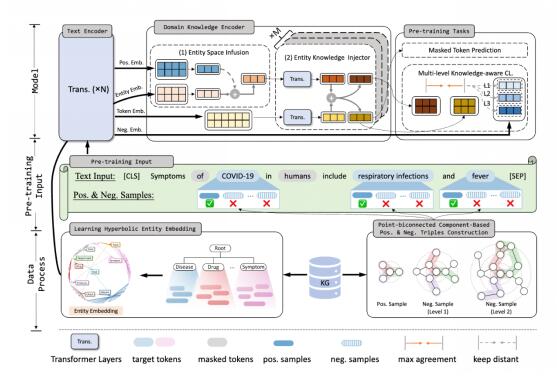
这一工作研究是基于上述领域KG的数据特性提出了一个简单但有效的统一框架来学习各种垂直领域的KEPLM。它分别通过双曲空间学习垂直领域图谱数据的分层语义信息来补充全局语义稀疏模块Hyperbolic Knowledge-aware Aggregator,通过捕捉领域图谱稠密的图结构构造基于点双联通分量的对比学习模块Multi-Level Knowledge-aware Augmenter。
我们选取了金融和医疗等领域的各种下游任务的全数据量和少样本数据量场景进行评测,结果体现出这个模型的优越性。
基于大语言模型的复杂任务认知推理算法CogTree
随着深度学习在自然语言处理、机器翻译等任务上的不断发展,人们对如何将深度学习应用到自然语言处理中越来越感兴趣,由此出现了大语言模型(例如GPT-3.5),并已在文本生成、情感分析、对话系统等多个任务上取得了重大突破。大语言模型通常基于大规模文本数据进行预训练,然后通过微调在特定任务上进行优化,以生成高质量的文本输出。然而,对于语言模型而言,复杂的逻辑推理问题和数学问题的求解仍然是很困难的。并且,传统的语言模型缺乏认知能力。在处理涉及冗长的推理链或多步解决方案的问题时,对于问题及其当前回答的评估是很重要的。然而,目前的方法例如Chain-of-thought等通常缺乏对于中间过程的验证。并且大型语言模型的部署和推理成本相对较高,特别是在利用无参数更新的推理增强技术时。这些技术需要大量的上下文和多步的答案生成,进一步增加了推理成本和时间。
这一工作研究面向轻量化大模型的复杂任务推理,使用较小规模的模型(7B),构建双系统生成推理树,大大增强模型在复杂数学问题和逻辑推理问题上的回答能力。提出了一种大模型面向复杂数学问题的求解方法。该方法基于人类的认知理论,通过两个系统:直觉系统和反思系统来模仿人类产生认知的过程。直觉系统负责产生原始问题的多个分解假设,反思系统对直觉系统产生的假设进行验证,并选择更有可能的假设进行后续生成,直到达到最终结果。通过上述双系统的迭代式生成,可以提升大模型的解题准确度。
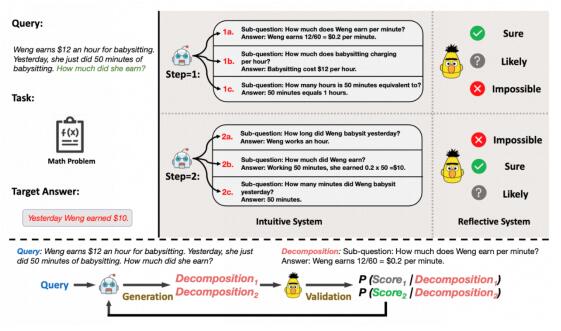
我们在Entailment Bank逻辑推理数据集以及GSM8K数学问题数据集上进行了测试,效果证明CogTree对大模型复杂任务上的回答准确率提升明显。
基于知识迁移的跨语言机器阅读理解算法
大规模预训练语言模型的广泛应用,促进了NLP各个下游任务准确度大幅提升,然而,传统的自然语言理解任务通常需要大量的标注数据来微调预训练语言模型。但低资源语言缺乏标注数据集,难以获取。大部分现有的机器阅读理解(MRC)数据集都是英文的,这对于其他语言来说是一个困难。其次,不同语言之间存在语言和文化的差异,表现为不同的句子结构、词序和形态特征。例如,日语、中文、印地语和阿拉伯语等语言具有不同的文字系统和更复杂的语法系统,这使得MRC模型难以理解这些语言的文本。为了解决这些挑战,现有文献中通常采用基于机器翻译的数据增强方法,将源语言的数据集翻译成目标语言进行模型训练。然而,在MRC任务中,由于翻译导致的答案跨度偏移,无法直接使用源语言的输出分布来教导目标语言。
这一工作提出了一种名为X-STA的跨语言MRC方法,遵循三个原则:共享、教导和对齐。共享方面,提出了梯度分解的知识共享技术,通过使用平行语言对作为模型输入,从源语言中提取知识,增强对目标语言的理解,同时避免源语言表示的退化。教导方面,本方法利用注意机制,在目标语言的上下文中寻找与源语言输出答案语义相似的答案跨度,用于校准输出答案。对齐方面,多层次的对齐被利用来进一步增强MRC模型的跨语言传递能力。通过知识共享、教导和多层次对齐,本方法可以增强模型对不同语言的语言理解能力。
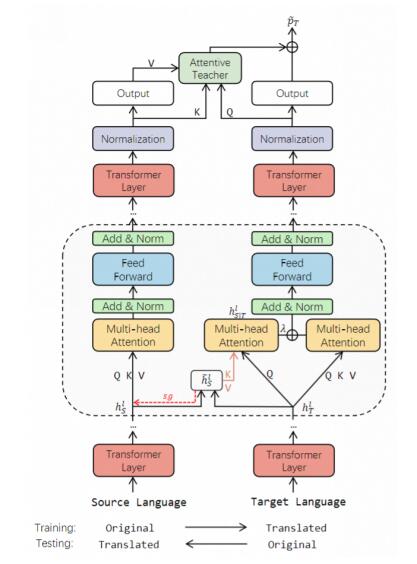
为了验证X-STA算法的有效性,我们在三个跨语言MRC数据集上进行了测试,效果证明X-STA对精度提升明显。
上述科研成果也在PAI产品的各个模块进行了深度的集成和整合,持续为PAI客户提供AI模型训练相关服务。其中,BeautifulPrompt技术已经作为SD WebUI的可扩展插件和PAI-EAS在线推理服务进行集成,使得PAI客户在5分钟内就可以在PAI-EAS上一键部署SD WebUI,使用各种AIGC文图生成功能。此外,PAI-QuickStart也集成了超过20个热门大语言模型,及其多种训练和推理方式,使客户更加简单地微调和部署大语言模型。在未来,我们也将在PAI平台上持续提供业界领先的算法和模型能力给广大客户。
论文信息
论文标题:BeautifulPrompt: Towards Automatic Prompt Engineering for Text-to-Image Synthesis
论文作者:曹庭锋、汪诚愚、刘冰雁、吴梓恒、朱金辉、黄俊
论文pdf链接:https://arxiv.org/abs/2311.06752
论文标题:Learning Knowledge-Enhanced Contextual Language Representations for Domain Natural Language Understanding
论文作者:徐如瑶、张涛林、汪诚愚、段忠杰、陈岑、邱明辉、程大伟、何晓丰、钱卫宁
论文pdf链接:https://arxiv.org/abs/2311.06761
论文标题:From Complex to Simple: Unraveling the Cognitive Tree for Reasoning with Small Language Models
论文作者:严俊冰、汪诚愚、张涛林、何晓丰、黄俊、张伟
论文pdf链接:https://arxiv.org/abs/2311.06754
论文标题:Sharing, Teaching and Aligning: Knowledgeable Transfer Learning for Cross-Lingual Machine Reading Comprehension
论文作者:曹庭锋、汪诚愚、谭传奇、黄俊、朱金辉
论文pdf链接:https://arxiv.org/abs/2311.06758